
Immer mehr Menschen nutzen LLMs direkt auf ihren PCs, um Abonnementkosten zu minimieren und mehr Privatsphäre und Kontrolle über ihre Projekte zu haben. Mit neuen und fortschrittlichen Open-Weight-Modellen sowie kostenlosen lokalen Tools experimentieren immer mehr Menschen direkt auf ihrem Laptop oder Desktop mit AI. RTX-GPUs beschleunigen diese Experimente und ermöglichen schnelle und flüssige AI. Mit den Updates von Project G-Assist können Laptop-Nutzer nun AI-gestützte Sprach- und Textbefehle zur Steuerung ihres PCs verwenden.
Der neueste RTX AI Garage-Blog von NVIDIA zeigt, wie Studenten, AI-Begeisterte und Entwickler schon heute LLMs auf PCs nutzen können:
- Ollama: Eine der einfachsten Möglichkeiten für den Einstieg. Dieses Open-Source-Tool bietet eine einfache Benutzeroberfläche für die Ausführung von und Interaktion mit LLMs. Benutzer können PDF-Dateien per Drag & Drop in Eingabefelder ziehen, Konversationen führen und sogar multimodale Workflows testen, die Texte und Bilder verbinden.
- AnythingLLM: Ermöglicht die Erstellung eines persönlichen AI-Assistenten. Läuft auf Ollama und ermöglicht Benutzern Notizen, Folien oder Dokumente hochzuladen, um einen Tutor zu erstellen. Der Assistent kann Quizfragen und Lernkarten für studentische Kursarbeiten generieren, die privat, schnell und kostenlos nutzbar sind.
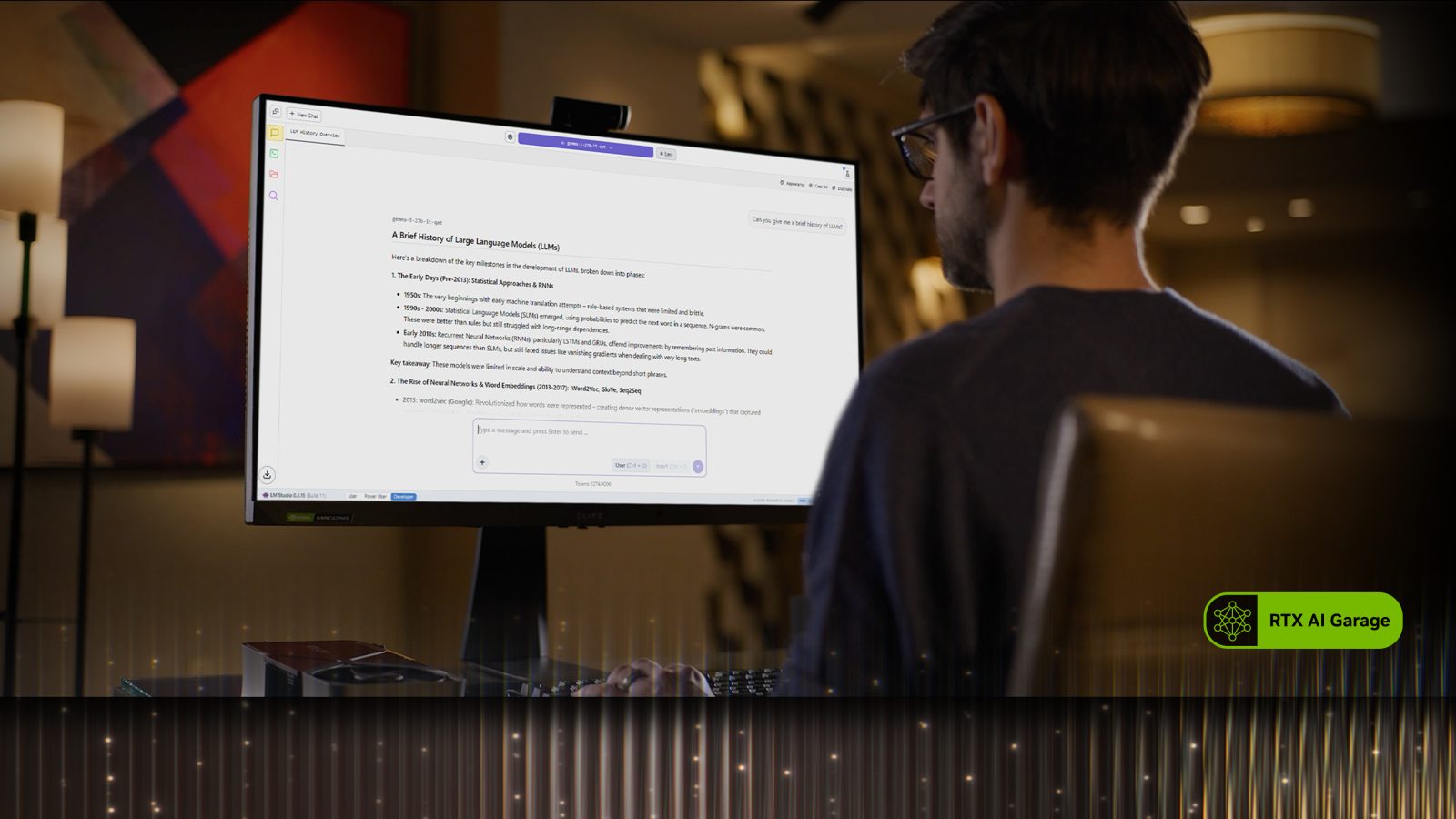
- LM Studio: Bietet Dutzende von Modellen, basiert auf dem beliebten llama.cpp-Framework und bietet eine benutzerfreundliche Oberfläche für die lokale Ausführung von Modellen. Benutzer können verschiedene LLMs laden, in Echtzeit mit ihnen chatten und sie sogar als lokale API-Endpunkte für die Integration in benutzerdefinierte Projekte verwenden.
- Project G-Assist: Lässt Nutzer den PC mit AI steuern. Mit den neuesten Updates können PC-Nutzer nun per Sprache oder Text die Einstellungen für Akku, Lüfter und Leistung anpassen.
Zu den neuesten Fortschritten bei RTX-AI-PCs gehören:
- Ollama erhält eine erhebliche Leistungssteigerung auf RTX: Die neuesten Updates ermöglichen bis zu 50% optimierte Leistung für OpenAI’s gpt-oss-20B und bis zu 60% schnellere Gemma 3-Modelle sowie eine intelligentere Modellplanung, um Speicherprobleme zu reduzieren und die Multi-GPU-Effizienz zu verbessern.
- Llama.cpp und GGML für RTX optimiert: Die neuesten Updates bieten eine schnellere und effizientere Inferenz auf RTX-GPUs, einschließlich Unterstützung für das NVIDIA Nemotron Nano v2 9B-Modell, standardmäßig aktivierte Flash Attention und CUDA-Kernel-Optimierungen.
- Das v0.1.18-Update für G-Assist kann über die NVIDIA App heruntergeladen werden und bietet neue Befehle für Laptop-Benutzer sowie eine verbesserte Antwortqualität.
- Microsoft hat Windows ML mit NVIDIA TensorRT für RTX-Beschleunigung veröffentlicht, das eine bis zu 50% schnellere Inferenz, eine optimierte Bereitstellung und Unterstützung für LLMs, Diffusion und andere Modelltypen auf Windows 11-PCs bietet.